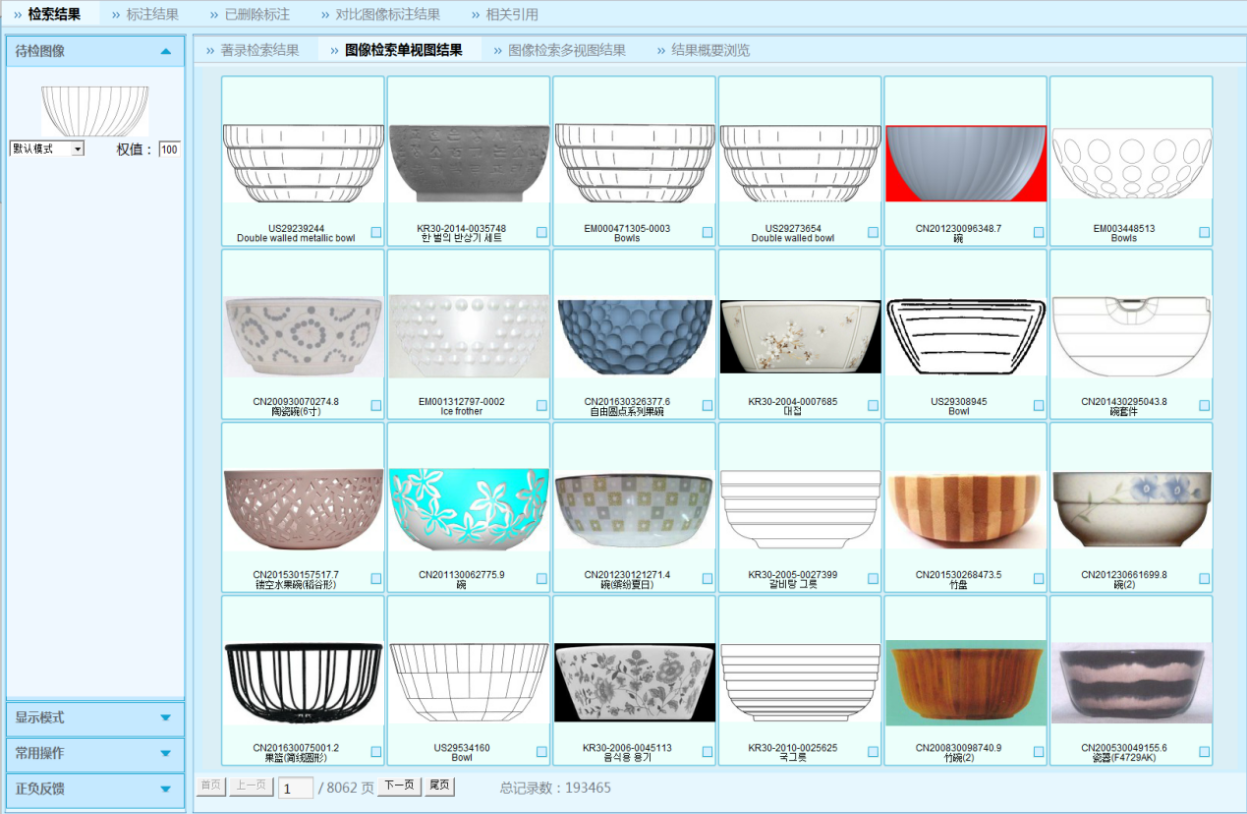
專利檢索與服務系統(Patent search and service system),以下簡稱S系統,是專利局信息化建設十一五規劃中的重大建設項目之一。S系統的系統架構設計是基于B/S架構進行開發設計的。審查員在確定檢索詞或檢索式后,點擊“檢索”向服務器(à檢索WEB服務器à檢索應用服務器)發送請求,服務器在接收到該請求之后,會調用檢索引擎的檢索接口進行檢索并將檢索式注冊到應用數據庫中,然后返回檢索結果。
TRS檢索引擎作為S系統的發動機,提供專利各類數據的索引和檢索服務,包括專利分類號、公告日、申請人、設計人等結構化數據的元數據檢索,以及專利名稱、摘要、權利要求書、說明書等非結構化數據的全文檢索。
搜索引擎功能實現了91個索引庫、23.1億條索引記錄、超20T的數據量,日均訪問量2500萬次,總請求平均響應時間低于60毫秒,記錄讀取平均響應時間低于50毫秒。
特點:
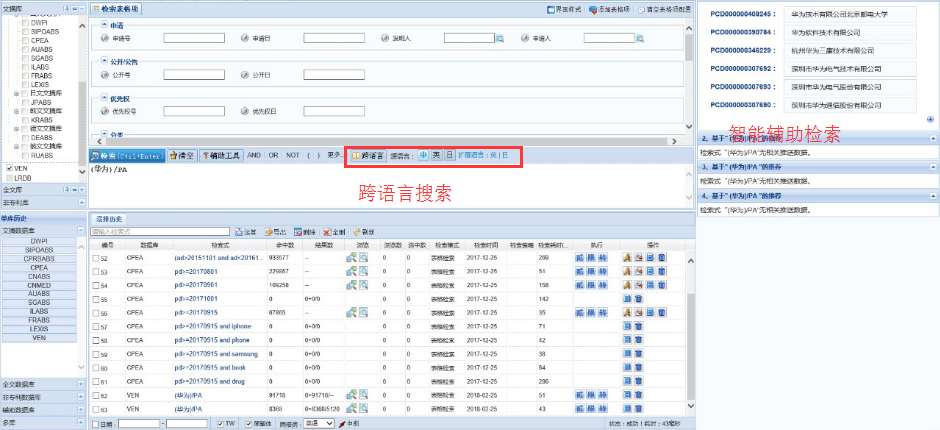
支持跨語言檢索
支持數值范圍檢索
提供查詢和統計分析功能
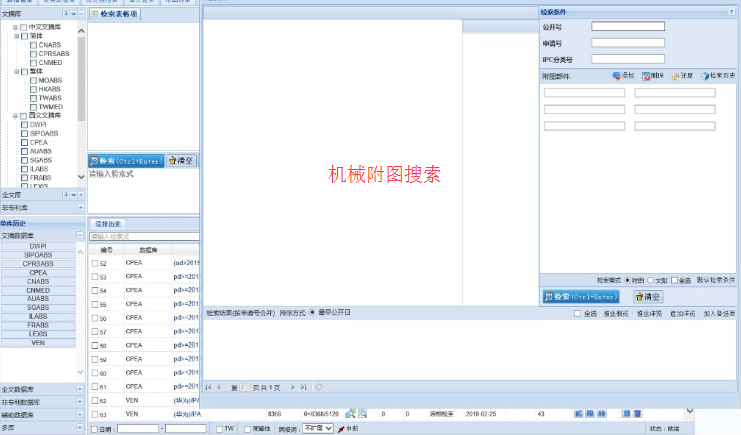
支持文本搜索,支持機械附圖搜索
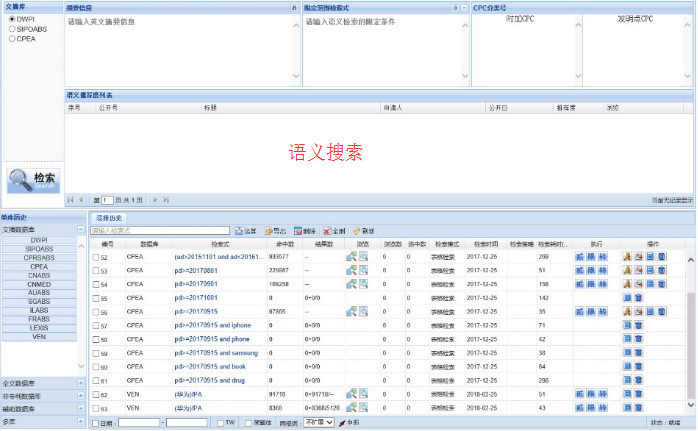
支持關鍵詞檢索,支持語義檢索
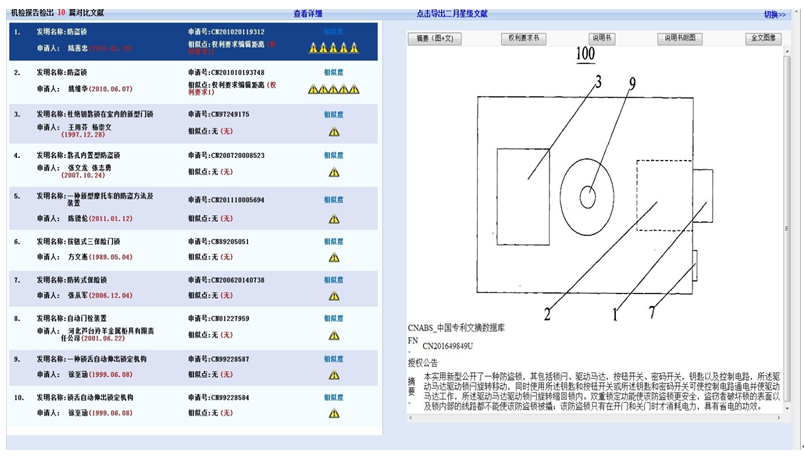
隨著我國從“中國制造”市場向“中國設計”市場轉型,國家大力推動各個重大領域的技術創新,我國的專利申請數量在快速上升,每年的專利申請數量已居國際前列。隨著申請量的飛速增長,惡意抄襲、低質量申請等問題在專利申請中層出不窮。龐大的專利申請對審查員的日常審查業務造成了巨大的壓力,為了減輕審查員的工作負擔,提高專利審查質量和公信度,國家知識產權局于2013年上線了實用新型機檢報告推送項目。經過幾年的努力,已經建成一體化的機檢報告生成系統,將申請接收、機檢報告生成、機檢報告結果推送等功能緊密結合,實現機檢報告業務的全流程服務。
目前,已經處理了近大幾百萬件實用新型申請。其中有10%左右的申請被判定為存在高相似度(四五星)文獻,高相似度文獻識別的準確率基本是100%。
發明機檢報告系統也已經上線,累計已處理發明申請幾百萬萬件(含歷史申請),其中有超過10%以上的申請被判定為四五級,即確定為抄襲。四五級識別的準確率基本是100%。
| 時間 |
申請件數(萬件) |
四五星文獻檢出量(件) |
四五星文獻檢出率 |
| 2013 |
83 |
72464 |
8.7% |
| 2014 |
101 |
48147 |
4.8% |
| 2015 |
109 |
121993 |
11% |
| 2016 |
138 |
247962 |
17% |
| 2017 |
157 |
118115 |
7.5% |
| 2018.1~11 |
198 |
275844 |
13.8% |
機檢報告系統總體運行穩定,能夠有效地識別出權利書、說明書、附圖明顯抄襲的申請。
機檢報告系統為專利審查工作提供了強有力的智能支持,降低審查開銷,促進審查資源的有效利用,切實推動專利審查質量的提升。
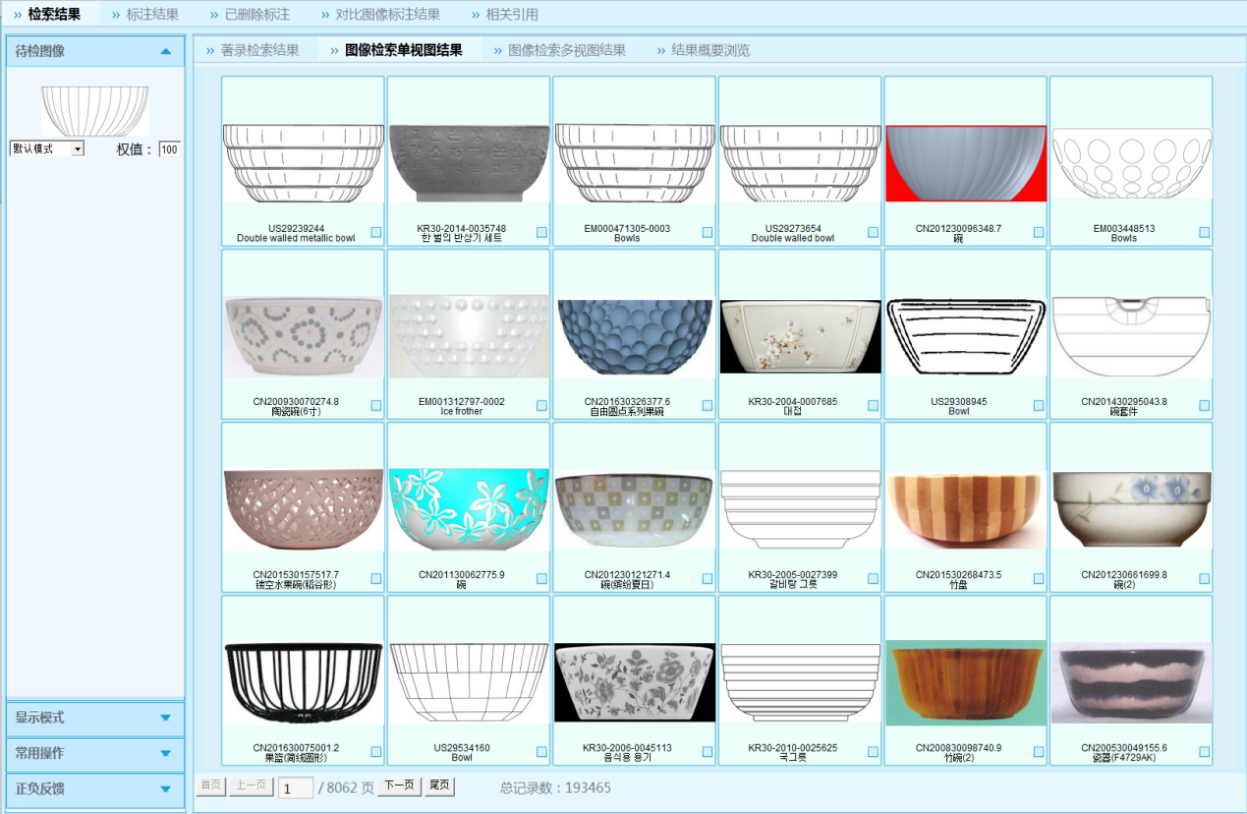
中國外觀設計智能檢索(以下簡稱D系統)具有智能化自動識別功能、高效準確的外觀設計專利圖形圖像計算機檢索系統, 是支撐國家知識產權局專利局審查工作的核心業務系統之一。
D系統基于計算機圖形圖像識別與檢索技術,依據一定的規則通過對外觀設計專利的圖形圖像進行自動識別和基本判斷,快速做出相同/相近似的初步判斷,準確過濾無價值的設計,將有價值的檢出對象框定在最小范圍內,使審查員對檢索系統檢出的有限數目對象進行相同/相近似的人工判斷。
外觀設計專利數據具有數據量大,數據類型復雜、圖像沒有統一標準等特征,因此在外觀設計專利數據上進行圖像檢索有很大的技術難度。D系統二期雖具備圖形檢索的功能,但存在檢索效率慢、檢索規模受限和檢索效果欠佳等問題。
拓爾思經過多年的研究實踐,實現前沿的圖形比對和圖像檢索技術,通過基于圖形內容的檢索,滿足了審查用戶對檢索效率和準確率需求;結合審查員檢索報告的匯總、分析和總結,形成了新的檢索模式進而提高檢索效率;并集成同近義詞擴展、跨語言擴展等輔助技術,進一步提升了檢索體驗。目前圖像檢索系統的D系統三期,支持包括中國、美國、日本、韓國、德國、WIPO、中國香港、中國澳門、中國臺灣等十多個國家、組織和地區的外觀設計專利數據檢索。
圖像檢索系統中在庫專利文獻數超過900萬件,視圖數量在4500萬幅以上,數據容量達5T以上,實現了“90%的圖形檢索任務都在5秒內完成檢索響應”的性能指標,超越了“90%以上的對比文件出現在檢索結果的前15%”的準確率指標。
DI inspiro系統是由知識產權出版社有限責任公司開發建設的新一代知識產權服務系統,是中國首家知識產權大數據與智慧服務的信息化應用工具,聚集了專利、商標、標準、期刊和法律文書等各類知識產權數據。可實現用戶對知識產權相關數據的同步檢索獲取、快捷統計分析和項目即時預警;滿足用戶對知識產權數據的個性化加工、項目的自主分級管理,以及集團內的信息共享;實現用戶的特定需求,如生物序列檢索、化學結構檢索、可視化檢索、侵權分析、聚類分析、關聯分析、預警設置和項目管理等。
DI Inspiro充分借鑒了國內外著名信息檢索系統的先進功能,并且針對國內用戶的使用習慣進行了改良性設計。具有數據全面可靠、功能專業、檢索效率高、用戶界面友好等特點,是企事業單位研發工程師、專利管理人員和專利咨詢師等相關人員進行技術調研、競爭性分析和法律風險預警的有力工具。
DI Inspiro提供了快捷檢索、表格檢索、號單檢索、可視化檢索、化學結構檢索和生物序列檢索等多種檢索方式。此外,DI Inspiro還配備了功能強大的輔助查詢工具,可實現IPC、專利權人、同義詞、國別代碼、省市代碼、號碼等字段的擴展檢索。用戶可以對檢索結果進行導出、收藏、統計篩選和在線分析,還可以對檢索策略和結果在線自建數據庫導航樹,實現保存和預警。


為了滿足商標申請用戶和社會公眾對商標數據信息的檢索需求,國家工商總局于2004年建立了商標網上檢索系統,為用戶免費提供商標注冊信息檢索服務。
系統主要提供如下服務:
近似檢索:在申請商標前,檢索被申請商標是否有相同近似,避免申請人的時間和經濟損失;
綜合檢索:用戶檢索商標的基本信息及其他業務信息;
狀態檢索:檢索商標的業務流程;
公告檢索:檢索公告信息;
錯誤反饋:如果發現商標信息有誤,可以通過填寫反饋單,商標局進行核實后會進行更正。
商標網上檢索自動化系統提供五種檢索服務及錯誤信息反饋功能,檢索服務包括:商標近似檢索、商標綜合信息檢索、商標狀態檢索、商標公告檢索和商品/服務項目檢索。
商標網上檢索系統將采用國產化、自主化為主的可擴展、動態配置技術路線。

專利導航,以專利信息資源利用和專利分析為基礎,把專利運用嵌入產業技術創新、產品創新、組織創新和商業模式創新之中,是引導和支撐產業科學發展的一項探索性工作。專利導航的主要目的是探索建立專利信息分析與產業運行決策深度融合、專利創造與產業創新能力高度匹配、專利布局對產業競爭地位保障有力、專利價值實現對產業運行效益有效支撐的工作機制,推動產業的專利協同運用,培育形成專利導航產業發展新模式。
專利導航分析系統實現了專利信息資源整合,依據規則粗加工和自動標引,從產業發展方向、城市產業定位、產業發展路徑三個維度提供決策參考。專利導航分析系統主要由數據交換系統、智能輔助標引系統和導航分析系統構成。

數據交換系統通過WEB Service接口定期從國家平臺獲取中外文專利題錄文摘數據,同時調用智能輔助標引系統獲取技術分支,根據來源EXCEL歷史標引數據標引技術分支,以及提取城市、發明人等導航分析關鍵屬性后,寫入發布分析庫,完成數據交換。
智能輔助標引系統在基于規則(檢索表達式),完成技術分支標引;
導航分析系統基于現有專利數據分析,分析維度為技術分支表、IPC分類、城市、申請人等相關屬性。
導航分析分為產業發展方向、城市產業定位、產業發展路徑三大模塊。每個模塊細分為若干子分析,分別生成圖表及表格。用戶可以對相應的分析進行單項及多項下載操作。